
milvus 를 사용한 대용량 임베딩 서치 시스템 아키텍쳐
사내에서 대량의 데이터에 대해 운영 목적으로 분석하는 시스템이 필요해서, 대용량의 임베딩 벡터에 대해 ANN 을 활용해 검색하는 시스템을 구축했어요. 그 중에서도 IVF_PQ 를 사용했는데, HNSW 등에 비해 상대적으로 느리지만 굉장히 효율적인 메모리 사용이 가능해서, 이를 채택했어요.
- IVF_PQ 에 관해서 자세히 알고싶으시다면 이전 글을 참고해주세요.
글을 읽기 전에 잠깐! 꼭 Milvus 를 써야하는지 혹은 쓴다면 Milvus 1.x 버전대를 써야하는지 꼭 점검해보시길 바라요. Production 용이라면 가급적 안썼으면 해요.
Elasticsearch 및 기타 분산 시스템과 달리 하나의 인덱스가 가용성을 위해 여러 Replica 에 복제되어서 검색되는 것이 지원되지 않아요. 관련 해서 이슈 를 남겼었는데, 의사소통 이슈가 있지만… 기본적으로 Mivlus V1 은 버린 프로젝트처럼 관리하지 않고 있기 때문이에요.
(추가로, 해당 프로젝트를 진행할 때는 2.0 및 1.x 에 대한 로드맵이 전혀 없었어요.)
설계 원칙
구조를 설명하기에 앞서, AS-IS와 TO-BE을 정리하고자해요.
AS-IS
기존에 같은 목적으로 Single Node 로 FAISS 서버가 있었으나, 여러가지 문제 사항들이 있었어요.
- Scale Out 이 어렵다.
- 하나의 Pod 에서 운영하고, 가용한 메모리를 크게 잡아서 운영 (ex. 32GiB or …)
- 초기 Index Build 시 데이터와 지속적으로 추가되는 데이터의 분포가 달라질 경우, 검색 퀄리티가 떨어질 수 있다.
- 검색 가능한 양이 제한되어있다.
- 인덱스가 분산되지 않으므로, Scale Up 할 수 있는 한계가 존재하므로 검색 가능한 양 자체가 제한
TO-BE
따라서, 이를 해결하기 위해 다음과 같은 요구사항이 필요해요.
- 하루에 n백만건 이상 추가되면서, 새로운 데이터가 실시간으로 검색 가능한 구조
- 데이터 수가 크게 증가하더라도, 검색 퀄리티가 유지되는 구조
- 데이터 수가 10배, 100배 증가하더라도 운영할 수 있는 확장이 가능한 구조
- 장애 상황 발생 시 복구 가능한 구조
Non-Goal
반면, Non-Goal 은 다음과 같아요.
- 메인 트래픽 (1000+ req/s) 또는 그 이상을 처리할 수 있는 구조
이는 중요하지 않아서라기보다는, 이를 위한 시스템에서는 더 많은 양의 리소스가 필요해요. 가령 이를 위해 메인 알고리즘을 HNSW 등으로 적용하는 등 고려할 사항들이 필요해요. (그러나, 일반적으로 IVF_PQ 는 HNSW 에 비해 느린 대신 메모리 사용량이 압도적으로 적어요.)
시스템 구성시 고려사항
일관된 검색 퀄리티 유지 및 Scalability 를 위해서 기존에 전체 데이터를 하나의 인덱스로 관리하던 구조에서, 적절한 시간 단위로 인덱스를 구축하도록 변경해야해요. 이를 위해서는 Trade-Off 가 있는데, 아래와 같아요.
- 긴 시간 단위의 인덱스 (→ 하나의 인덱스를 크게 가져가는 경우)
- PQ 를 위한 메모리 Overhead 가 적으므로, 메모리 효율적이에요.
- 인덱스가 만들어지기 전까지 Brute-force 로 검색해야하는 데이터가 커져서, CPU 비효율적 및 Search Time Response 가 커져요.
- 짧은 시간 단위의 인덱스 (→ 하나의 인덱스를 작게 가져가는 경우)
- PQ 를 위한 메모리 Overhead 가 커지므로, 메모리 비효율적이에요.
- 인덱스가 만들어지기 전까지 Brute-force 로 검색해야하는 데이터가 작아져서, CPU 효율적 및 Search Time Response 가 짧아져요.
IVF_PQ 의 구조상 인덱스가 많이 생기면 오버헤드가 굉장히 커지므로, 들어오는 데이터의 분포에 맞춰서 인덱스가 하루에 하나만 생기도록 적절한 범위 내에서 설정하는 것이 좋다고 판단했어요.
milvus 의 경우 index_file_size 에 따라 이를 넘을 때 인덱스를 만드므로, 하루에 딱 인덱스가 1개만 생기도록 어느정도 버퍼를 둬서 index_file_size 를 설정했어요. 이는 계산 사이트에서 계산할 수 있는데, milvus v1.1.1 에서는 최대 128GB까지 설정 가능해요. 레퍼런스 (tmi; 초기에는 4GB 가 제한이라 굉장히 빡빡했는데, 현재 사용가능한 1 버전 대의 최신 버전에서 풀려서 사용하고 있어요)
그러나 이렇게 설정하더라도 문제가 있는데, 이는 milvus 가 File System 에 지속적으로 추가되는 환경에서 너무 비효율적인 파일 쓰기 문제가 있어요.
insert 시에 파일을 주기적으로 append 하는게 아니라, 작은 파일들을 여러개 만들고 이를 merge 하는 형태라 2GB 의 파일이 쌓여있을 때 10MB 를 더한다면, 처리량이 2GB+10MB 만큼 잡아먹어요. (두 파일을 merge 후에 soft-delete, merge 시에 메모리에 올려두기까지 해서, 더 비효율적)
따라서 이를 해결하기 위해, 가급적 작은 단위 (256MB or 128MB) 로 인덱스를 만들고, 최대 하루치만큼의 데이터를 검색하도록 하는 Short-term Cluster 를 분리했어요.
이를 통해 얻는 장단점은 다음과 같아요.
- 장점
- File System 에 적은 부하 (한번에 최대 소모되는 파일시스템 처리량이 256MB 또는 128MB 로 제한됨)
- 대량의 데이터에 대해 검색하는 Long-term 의 경우는 파일 시스템 단에서의 부하를 최대한 줄여서 안정적인 운영 가능
- 짧은 단위로 데이터를 인덱싱해서, Brute-force 의 부하를 줄일 수 있음!
- 또한, 인덱싱 시에 걸리는 CPU 부하는, 명시적으로 다른 Cluster 이므로 상대적으로 부하가 더 큰 Long-term Cluster 와 분리되어서 분산되고, 안정적임
- 단점
- 클러스터 개수가 늘어남에 따라 복잡한 구성
- 주기적인 migration 이 필요
- 처리량 때문에 EFS 의 명시적 분리가 필요해서 추가 작업 필요
이는 분리했을 때의 장점이 압도적으로 크므로, Cluster 를 분리해서 설계했어요.
구조
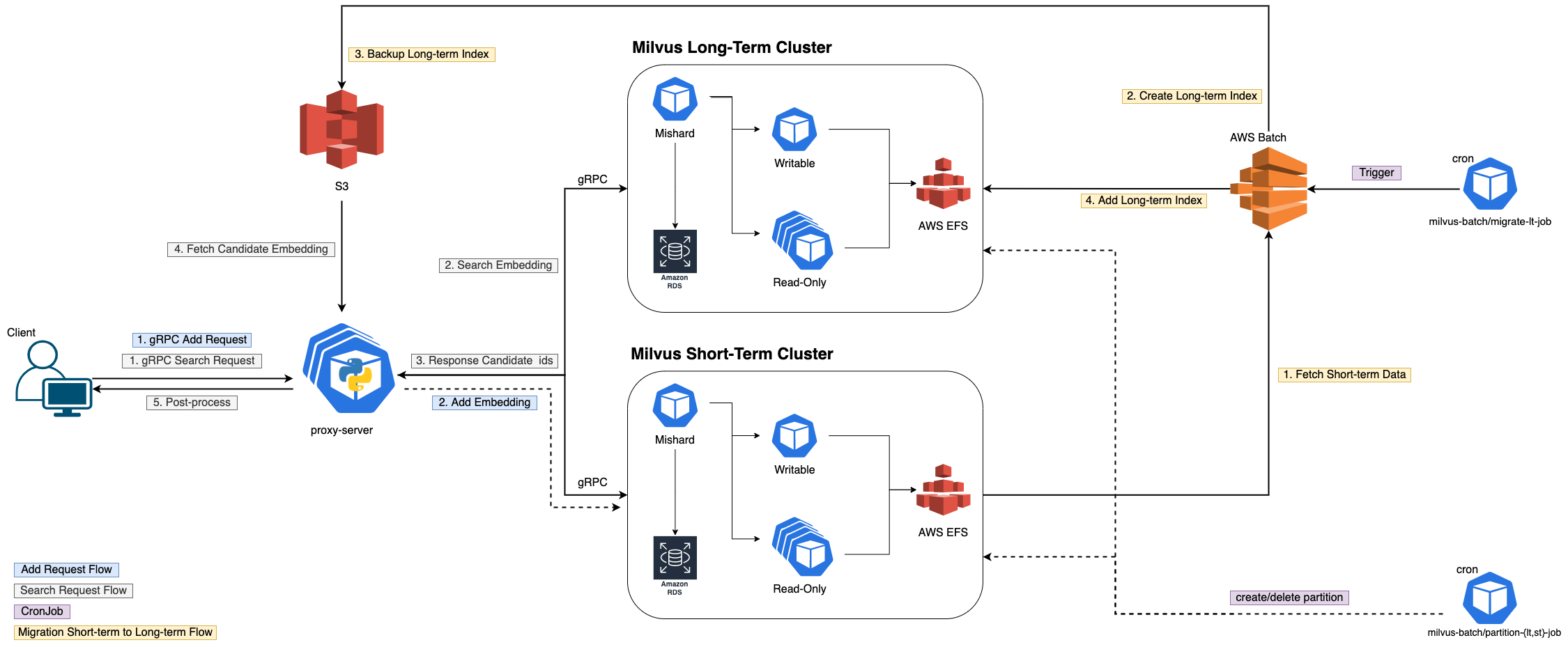
전체적인 시스템 구조는 위와 같아요. 각 Cluster 가 보다시피 분리되어있고, 각 Flow 에 따라 추가 설명을 드리려고해요. Scale-out 가능한 Pod 들은 그림과 같이 여러개의 아이콘을 겹쳐놓아서 표시했어요.
데이터 추가
Add Request Flow
- Client 가 요청하면, proxy 서버가 요청을 받아서 Short-term Cluster 에 add 해요. (milvus sdk 로 요청)
- Flush 전까지는 Writable 이 memory 에 들고있다가 buffer 가 차거나 혹은
auto_flush_interval시에 Writable 이 EFS 에 쓰고, 파일 시스템의 변경사항을 metadata 로 RDS 에 저장- buffer 에만 있을 때에는 검색되지 않아요. 실제 파일에 써지고 메타데이터가 변경되어야 검색 가능해요! (이는 Read-Only Pod 의 명시적 분리 때문이에요)
검색
Search Request Flow
- Client 가 요청하면, milvus-image-server 가 proxy 로 요청을 받아서 스레딩을 통해 어제까지의 데이터를 Long-Term 에 검색 요청을 하고, 오늘 데이터를 Short-Term 에 검색 요청을 날린 후 Join 해요. (milvus sdk 로 요청)
- milvus 로부터 Candidate vector ids 와 scores(혹은 cosine sim. 값)를 받아서 도메인에 따른 특정 비즈니스 로직을 처리 후에 필요하면 후처리를 진행해요.
- 모든 요청을 후처리하기에는 부하가 너무 크기 때문이에요.
- 실험적으로 놓치는 비율 대비 얻는 이득을 계산해서 진행했어요. (Recall 과 Throughput 의 Trade-Off 실험 후 결정)
- candidate id 로 S3 의 embedding 을 받아온 후, 실제 임베딩에 대해 distance 를 계산해서 리턴해요
- proxy 의 한 Request 에 10개의 쿼리 벡터가 있고, top 10 에 대해 처리한다고 하면 1 Request 당 최대 10 * 10 * 2 (long-term & short-term) →
S3 에 200 Fetch / req가 발생해요. 너무 많은 네트워크/스레딩 병목이 생겨서 결과가 느려져요.
- proxy 의 한 Request 에 10개의 쿼리 벡터가 있고, top 10 에 대해 처리한다고 하면 1 Request 당 최대 10 * 10 * 2 (long-term & short-term) →
메타데이터 관리
- Partition Job 들은 모든 시스템들이 K8S 에서 배포되므로, K8S 의 CronJob 으로 관리해요.
- 하루에 한번 주기적으로 Milvus 파티션을 주기적으로 삭제하고, 새로 생성해요.
- Short-term 데이터를 Long-term 용으로 인덱싱 후 Migration
- 하루에 한번 주기적으로 cronjob 으로 떠서 AWS Batch 를 호출해요. 그 후 batch job 의 status 를 주기적으로 fetch 해서 실패 시 slack 에 노티하도록 구성했어요.
- Batch Job 내부에서는 아래와 같은 일을 순차적으로 해요.
- Short-term Cluster 의 RDS 에서 어제 날짜의 데이터 정보들을 (메타데이터) 가져와요.
- 해당 데이터로부터 EFS 에 접근해서 Local Container 내부에 데이터를 복사해요.
- Local Container 내부에 Milvus 를 구성해서 (메타데이터 저장용 MySQL 포함) 해당 메타데이터를 MySQL 에 복사한 뒤 milvus command 로 Long-term 의 구성과 같도록 구성을 변경해요. (
index_file_size등 변경) - 파일이 정상적으로 다 merge 가 되었는지 계속 확인하면서 (내부 MySQL 에 쿼리를 날려서 확인) 일정 시간 내에 완료되지 않으면 에러로 간주하고 비정상 종료해요.
- (파일이 다 merge 되어서 한개의 파일임이 보장되었을 때) 인덱스 생성을 호출해서 인덱싱해요. 마찬가지로 일정 시간 내에 완료되지 않으면 에러로 간주하고 비정상 종료해요.
- 새로 구성된 데이터 파일 및 메타데이터를 S3 에 백업해요.
- 새로 구성된 데이터 파일을 Long-term EFS 에 Copy 해요.
- 새로 구성된 메타데이터를 Long-term RDS 에 Insert Query 로 Insert 해요.
Migration 과 관련해서는 간단하게 작성한 코드를 맨 아래에 부록으로 공유드려요.
위와 같은 구성을 통해, 얻은 것은 다음과 같아요.
- 현재 n억건 정도의 데이터를 p99 기준 3초 이내에 처리하도록 구성했어요.
- 데이터 양이 10억건 혹은 100억건, 1000억건까지 늘어나더라도, 충분히 대응 가능한 구조에요.
- 해당 글을 작성하는 시점인 2022.01.03 기준으로, 위 시스템을 배포한 후 6달 이상 큰 문제 없이 안정적으로 운영 중인 시스템!
부록
아래 파일을 Migration 을 위한 코드에요. (이미 충분히 길지만…) 길이를 위해 필요한 import 및 기타 민감 정보를 제거했어요.
추가로, 아래 작업을 위해 Milvus 공식 레퍼런스 및 수많은 소스코드들과 여러 자료들을 보면서 한땀한땀 구성한 코드에요.
# migrate.py
FILE_TYPE_RAW_FILE = 1
FILE_TYPE_TO_BE_INDEX_FILE = 2
FILE_TYPE_INDEX_FILE = 3
FILE_TYPE_WILL_BE_DELETED_FILE = 4
FILE_TYPE_BACKUP_RAW_VECTOR_FILE = 7
ENGINE_TYPE_FLAT = 1
TABLES_COLUMN = [
"table_id",
"state",
"dimension",
"created_on",
"flag",
"index_file_size",
"engine_type",
"index_params",
"metric_type",
"owner_table",
"partition_tag",
"version",
"flush_lsn",
]
TABLEFILES_COLUMN = [
"table_id",
"segment_id",
"engine_type",
"file_id",
"file_type",
"file_size",
"row_count",
"updated_time",
"created_on",
"date",
"flush_lsn",
]
MAX_WAIT_MINITUES = int(os.environ.get("MAX_WAIT_MINITUES", 60))
def fetch_tables_info(cursor, *, collection: str, start_date: datetime):
partition_tags = get_partition_tags(
prefixes=[MILVUS_ALL_PARTITION_PREFIX], start_date_str=start_date.strftime("%Y-%m-%d")
)
sql = f"""
SELECT
{",".join(["t." + c for c in TABLES_COLUMN])}
FROM
Tables t
WHERE
t.owner_table = "{collection}"
AND t.partition_tag IN ({",".join(['"' + tag + '"' for tag in partition_tags])})
"""
cursor.execute(sql)
result = cursor.fetchall()
return result
def fetch_tablefiles_info(*, cursor, collection: str, start_date: datetime, is_merge: bool = False):
partition_tags = get_partition_tags(
prefixes=[MILVUS_ALL_PARTITION_PREFIX], start_date_str=start_date.strftime("%Y-%m-%d")
)
file_types = (
[FILE_TYPE_RAW_FILE, FILE_TYPE_TO_BE_INDEX_FILE, FILE_TYPE_BACKUP_RAW_VECTOR_FILE]
if is_merge
else [FILE_TYPE_RAW_FILE, FILE_TYPE_INDEX_FILE, FILE_TYPE_BACKUP_RAW_VECTOR_FILE]
)
file_types = [str(f) for f in file_types]
sql = f"""
SELECT
{",".join(["tf." + c for c in TABLEFILES_COLUMN])}
FROM
TableFiles tf
WHERE
tf.table_id IN (
SELECT table_id FROM Tables t
WHERE
t.owner_table = "{collection}"
AND t.partition_tag IN ({",".join(['"' + tag + '"' for tag in partition_tags])})
)
AND tf.file_type IN ({",".join(file_types)})
"""
cursor.execute(sql)
result = cursor.fetchall()
if is_merge:
# Overwrite
file_type_idx = TABLEFILES_COLUMN.index("file_type")
engine_type_idx = TABLEFILES_COLUMN.index("engine_type")
tmp_result = []
for r in result:
r = list(r)
r[file_type_idx] = FILE_TYPE_RAW_FILE
r[engine_type_idx] = ENGINE_TYPE_FLAT
tmp_result.append(tuple(r))
result = tuple(tmp_result)
return result
def insert_milvus_mysql(*, cursor, table: str, sql_result: tuple, overwrite=True):
mode = "REPLACE" if overwrite else "INSERT IGNORE"
if table == "Tables":
cols = TABLES_COLUMN
elif table == "TableFiles":
cols = TABLEFILES_COLUMN
else:
raise ValueError(f'Invalid table: {table}, must be "Tables" or "TableFiles"!')
try:
if len(sql_result) > 0:
values = ",\n".join([str(row) for row in sql_result])
sql = f"""
{mode} INTO {table} ({",".join(cols)})
VALUES
{values}
"""
cursor.execute(sql)
result = cursor.fetchall()
except TypeError:
pass
def copy_tablefiles(*, tablefiles_info: Tuple, src_folder_path: str, trg_folder_path: str):
for tablefiles_row in tablefiles_info:
table_id = tablefiles_row[TABLEFILES_COLUMN.index("table_id")]
segment_id = tablefiles_row[TABLEFILES_COLUMN.index("segment_id")]
segment_folder_path = os.path.join(table_id, segment_id)
os.makedirs(os.path.join(trg_folder_path, segment_folder_path), exist_ok=True)
for filename in os.listdir(os.path.join(src_folder_path, segment_folder_path)):
src_filepath = os.path.join(src_folder_path, segment_folder_path, filename)
trg_filepath = os.path.join(trg_folder_path, segment_folder_path, filename)
shutil.copy(src_filepath, trg_filepath)
# EFS 성능에 쓰로틀을 줄 수 있어서, 세그먼트 단위로 복사하고 sleep
sleep(10)
def backup_tablefiles(s3_client, *, tablefiles_info: Tuple, s3_folder: str):
for tablefiles_row in tablefiles_info:
table_id = tablefiles_row[TABLEFILES_COLUMN.index("table_id")]
segment_id = tablefiles_row[TABLEFILES_COLUMN.index("segment_id")]
segment_folder_path = os.path.join(table_id, segment_id)
for filename in os.listdir(os.path.join(MILVUS_LOCAL_TABLES_PATH, segment_folder_path)):
filepath = os.path.join(segment_folder_path, filename)
response = s3_client.upload_file(
os.path.join(MILVUS_LOCAL_TABLES_PATH, filepath),
AWS_BACKUP_BUCKET,
f"{s3_folder}/tablefiles/{filepath}",
)
def check_merge(*, cursor, milvus_client, collection):
index_file_size_sql = f"""
SELECT
index_file_size
FROM
Tables
WHERE
table_id = "{collection}"
"""
cursor.execute(index_file_size_sql)
index_file_size = cursor.fetchall()[0][0]
sql = """
SELECT
file_type, file_size
FROM
TableFiles
"""
for i in range(MAX_WAIT_MINITUES):
milvus_client.flush(collection_name_array=[collection])
cursor.execute(sql)
results = cursor.fetchall()
if len(results) < 2:
return
# Soft Delete 파일이 없으면서 가장 작은 두개의 파일을 합쳐도 index_file_size 보다 작다면 Merge Complete
results = sorted(results, key=lambda result: result[1], reverse=True)
check = all(
[
file_type == FILE_TYPE_RAW_FILE
or file_type == FILE_TYPE_INDEX_FILE
or file_type == FILE_TYPE_BACKUP_RAW_VECTOR_FILE
for file_type, _ in results
]
)
if check and results[-1][1] + results[-2][1] > index_file_size:
return
# Sleep
sleep(60)
raise ValueError("Merge Hanging! Exited.")
def check_indexing(*, conn, cursor, client, collection_name):
sql = f"""
SELECT
{",".join(["tf." + c for c in TABLEFILES_COLUMN])}
FROM
TableFiles tf
"""
file_type_idx = TABLEFILES_COLUMN.index("file_type")
row_count_idx = TABLEFILES_COLUMN.index("row_count")
for i in range(MAX_WAIT_MINITUES):
cursor.execute(sql)
results = cursor.fetchall()
conn.commit()
client.compact(collection_name=collection_name)
client.flush(collection_name_array=[collection_name])
_, result = client.get_collection_stats(collection_name)
check = all([r[file_type_idx] in (FILE_TYPE_INDEX_FILE, FILE_TYPE_BACKUP_RAW_VECTOR_FILE) for r in results])
if check:
return
# alpha 에서는 데이터가 거의 없어서, 인덱싱 자체가 안될 수 있으므로 예외를 위해 처리
if all([r[row_count_idx] < 4096 for r in results if r[file_type_idx] == FILE_TYPE_RAW_FILE]):
return
# Sleep
sleep(60)
raise ValueError("Indexing Hanging! Exited.")
def force_create_index(*, conn, cursor):
create_index_sql = f"""
UPDATE
TableFiles tf
SET
tf.file_type = {FILE_TYPE_TO_BE_INDEX_FILE}
WHERE
tf.file_type = {FILE_TYPE_RAW_FILE}
"""
cursor.execute(create_index_sql)
conn.commit()
sql = """
SELECT
file_type, file_size
FROM
TableFiles
"""
for i in range(MAX_WAIT_MINITUES):
# DB 에서 Fetch
cursor.execute(sql)
results = cursor.fetchall()
check = all(
[
file_type == FILE_TYPE_INDEX_FILE or file_type == FILE_TYPE_BACKUP_RAW_VECTOR_FILE
for file_type, _ in results
]
)
if check:
return
# Sleep
sleep(60)
raise ValueError("Indexing Hanging! Exited.")
if __name__ == "__main__":
from argparse import ArgumentParser
import boto3
import pymysql
milvus_client = Milvus(###, ###)
s3_client = boto3.client("s3")
parser = ArgumentParser(description="Migrate Milvus Short-term to Long-term")
parser.add_argument(
"--start-timestamp-utc",
default=None,
type=int,
help="Optional) timestamp of start_date (date -u +%s) If not provided, `end_date - timedelta(days=1)`",
)
parser.add_argument(
"--end-timestamp-utc",
required=True,
type=int,
help="timestamp of end_date (date -u +%s)",
)
args = parser.parse_args()
end_date = datetime.fromtimestamp(args.end_timestamp_utc, tz=TIMEZONE)
start_date = (
end_date - timedelta(days=1)
if args.start_timestamp_utc is None
else datetime.fromtimestamp(args.start_timestamp_utc, tz=TIMEZONE)
)
lt_collection = ###
st_collection = ###
try:
lt_conn = pymysql.connect(
host=###,
user=###,
password=###,
db=###,
charset="utf8",
autocommit=True,
)
st_conn = pymysql.connect(
host=###,
user=###,
password=###,
db=###,
charset="utf8",
autocommit=True,
)
local_conn = pymysql.connect(
host=###,
user=###,
password=###,
db=###,
charset="utf8",
autocommit=True,
)
lt_cursor = lt_conn.cursor()
st_cursor = st_conn.cursor()
local_cursor = local_conn.cursor()
tables_sql = f"""
SELECT
dimension, index_file_size, engine_type, index_params, metric_type
FROM
Tables
WHERE
table_id = "{lt_collection}"
"""
lt_cursor.execute(tables_sql)
result = lt_cursor.fetchall()
(dimension, index_file_size, engine_type, index_params, metric_type) = result[0]
# Create Collection & Index
param = {
"collection_name": lt_collection,
"dimension": dimension,
"index_file_size": index_file_size // 1024 // 1024,
"metric_type": metric_type,
}
index_params = json.loads(index_params)
n_iter = (end_date - start_date).days
for i in range(n_iter):
first_date = start_date + timedelta(days=i)
second_date = first_date + timedelta(days=1)
# Fetch Infos
tables_info = fetch_tables_info(cursor=st_cursor, collection=st_collection, start_date=first_date)
tablefiles_info = fetch_tablefiles_info(
cursor=st_cursor, collection=st_collection, start_date=first_date, is_merge=True
)
st_conn.commit()
# Copy File
copy_tablefiles(
tablefiles_info=tablefiles_info,
src_folder_path=MILVUS_SHORT_TERM_TABLES_PATH,
trg_folder_path=MILVUS_LOCAL_TABLES_PATH,
)
# Short-term 의 파일들 metadata 변경
tmp_tables_info = []
index_file_size_idx = TABLES_COLUMN.index("index_file_size")
index_params_idx = TABLES_COLUMN.index("index_params")
owner_table_idx = TABLES_COLUMN.index("owner_table")
for info in tables_info:
info = list(info)
info[index_file_size_idx] = index_file_size
info[index_params_idx] = "{}"
info[owner_table_idx] = lt_collection
tmp_tables_info.append(tuple(info))
tables_info = tuple(tmp_tables_info)
# Update MySQL
insert_milvus_mysql(cursor=local_cursor, table="Tables", sql_result=tables_info, overwrite=False)
insert_milvus_mysql(cursor=local_cursor, table="TableFiles", sql_result=tablefiles_info, overwrite=True)
local_conn.commit()
# 매번 create_index 를 해서 merge trigger & indexing
index_response = milvus_client.create_index(lt_collection, engine_type, index_params)
check_indexing(conn=local_conn, cursor=local_cursor, client=milvus_client, collection_name=lt_collection)
# Local 에서 새로 Fetch
new_tables_info = fetch_tables_info(cursor=local_cursor, collection=lt_collection, start_date=first_date)
new_tablefiles_info = fetch_tablefiles_info(
cursor=local_cursor, collection=lt_collection, start_date=first_date, is_merge=False
)
# Long-term 에 Copy File
copy_tablefiles(
tablefiles_info=new_tablefiles_info,
src_folder_path=MILVUS_LOCAL_TABLES_PATH,
trg_folder_path=MILVUS_LONG_TERM_TABLES_PATH,
)
# Long-term 에 Update MySQL
insert_milvus_mysql(cursor=lt_cursor, table="Tables", sql_result=new_tables_info, overwrite=False)
insert_milvus_mysql(cursor=lt_cursor, table="TableFiles", sql_result=new_tablefiles_info, overwrite=True)
lt_conn.commit()
# AWS S3 에 업로드
s3_folder = ###
tables_info_upload_response = s3_client.put_object(
Body=f"{str(TABLES_COLUMN)}\n{str(new_tables_info)}",
Bucket=AWS_BACKUP_BUCKET,
Key=f"{s3_folder}/tables/sql_result",
)
tablefiles_info_upload_response = s3_client.put_object(
Body=f"{str(TABLEFILES_COLUMN)}\n{str(new_tablefiles_info)}",
Bucket=AWS_BACKUP_BUCKET,
Key=f"{s3_folder}/tablefiles/sql_result",
)
# TableFiles 를 AWS S3 에 업로드
backup_tablefiles(s3_client, tablefiles_info=new_tablefiles_info, s3_folder=s3_folder)
finally:
lt_conn.close()
st_conn.close()
local_conn.close()